
Understanding Memory Latency Fundamentals
We all seek faster computers and more responsive systems. From intense gaming sessions to complex data analysis, smooth performance is essential. While many focus on the processor or graphics card, memory is often the unsung hero. It greatly impacts how quickly your computer can access and process information.
It’s not just about how much data your memory can handle (bandwidth). It’s critical how fast it responds to a request. This swiftness is known as low-latency memory. It can make a significant difference in your system’s overall feel and speed.
In this comprehensive guide, we will delve into memory latency in depth. We will define what it truly means and how it’s accurately measured. You’ll understand the key differences between latency and bandwidth. We will also explore which applications benefit most from low latency. Furthermore, we’ll trace the evolution of memory technology and examine specialized, low-latency solutions. Join us as we explain this crucial aspect of computer performance.
At its core, memory latency refers to the time delay between when a central processing unit (CPU) initiates a request for data from the main memory (RAM) and when that data is actually delivered and available to the CPU. It’s the “wait time” for information. In simpler terms, it refers to how quickly your system memory responds to a request. Memory latency is a critical factor impacting application performance, as the CPU often idles while waiting for data.
This delay is measured in two primary ways:
- Clock Cycles: This refers to the number of clock cycles required for the memory module to respond to a request. It’s often seen in specifications like CAS Latency (CL).
- Nanoseconds (ns): This is the actual time duration, measured in billionths of a second. It provides a more accurate, real-world representation of latency.
If the data required by the processor is not present in its faster, closer caches (L1, L2, L3), the CPU must reach out to the main memory. This communication with external memory cells introduces a significant delay, making memory latency a crucial bottleneck in many computing tasks. To understand the magnitudes, consider that an L1 cache reference might take 0.5 ns, while a main memory reference can take around 100 ns. You can explore more about these time differences on Colin Scott’s Interactive Latencies page.

What are CAS Latency (CL) and SPD?
When discussing memory latency, two terms frequently appear: CAS Latency (CL) and SPD.
CAS Latency (CL) is a key timing parameter for RAM. It represents the number of clock cycles it takes for the memory controller to access a specific column in a memory module, once the row has been activated. It’s the delay between the memory controller sending a column address and the data becoming available. For instance, a DDR4-3200 CL16 module means it takes 16 clock cycles to deliver data after a column address is requested. While a lower CL number generally indicates better performance, it’s crucial to remember that CL is measured in clock cycles, not time. As memory speeds (and thus clock frequencies) increase, the duration of each clock cycle decreases. This means a higher CL in a faster module might still result in the same or even lower true latency in nanoseconds compared to a lower CL in a slower module.
SPD (Serial Presence Detect) is a standard feature on all modern RAM modules. It’s a small chip on the memory stick that stores vital information about the module’s characteristics, including its capacity, manufacturer, and, crucially, its supported speeds and corresponding timing parameters (such as CL, tRCD, tRP, and tRAS). When you install RAM into your system, the motherboard’s BIOS reads the SPD data to automatically configure the memory settings. This ensures compatibility and allows the system to operate the RAM at its rated specifications, often adhering to JEDEC (Joint Electron Device Engineering Council) standards. While SPD provides default settings, users can frequently manually adjust timings in the BIOS (e.g., via XMP for Intel or EXPO for AMD profiles) to achieve higher performance or lower latency than the default SPD values. You can learn more about SPD on Wikipedia’s Serial Presence Detect page.
Calculating True Latency in Nanoseconds
To get a true measure of memory latency that allows for direct comparison across different memory speeds and CL ratings, we convert clock cycles into nanoseconds. This is often referred to as “real latency” or “absolute latency.”
The formula for calculating true latency in nanoseconds is:
True Latency (ns) = (CAS Latency * 2000) / Data Rate (MT/s)
Let’s break down the components:
- CAS Latency (CL): The number of clock cycles for the CAS.
- 2000: This constant converts the data rate from megatransfers per second (MT/s) to nanoseconds per clock cycle. (Since 1 MT/s = 1,000,000 transfers/second, and 1 second = 1,000,000,000 nanoseconds, the conversion factor becomes 1,000,000,000 / 1,000,000 = 1000, and since DDR transfers data on both rising and falling edges of the clock, the effective clock rate is half the data rate, hence 2000).
- Data Rate (MT/s): The effective speed of the memory, often quoted in MHz or MT/s (e.g., DDR5-6000 means 6000 MT/s).
Example Calculation: Consider a modern DDR5 kit rated for 6000 MT/s with CL30: True Latency (ns) = (30 * 2000) / 6000 = 60000 / 6000 = 10 nanoseconds
Let’s compare this to an older DDR4 kit, say DDR4-3200 CL16: True Latency (ns) = (16 * 2000) / 3200 = 32000 / 3200 = 10 nanoseconds
As you can see from these examples, a DDR5-6000 CL30 kit and a DDR4-3200 CL16 kit have roughly the same true latency in nanoseconds. This illustrates the “latency paradox” — as memory speeds increase, CAS latency numbers tend to go up. Still, the actual time delay (in nanoseconds) often remains similar or even improves slightly due to the faster clock cycles. An ideal real latency for memory is frequently considered to be around 10 nanoseconds, as significantly lowering it can incur disproportionately higher costs.
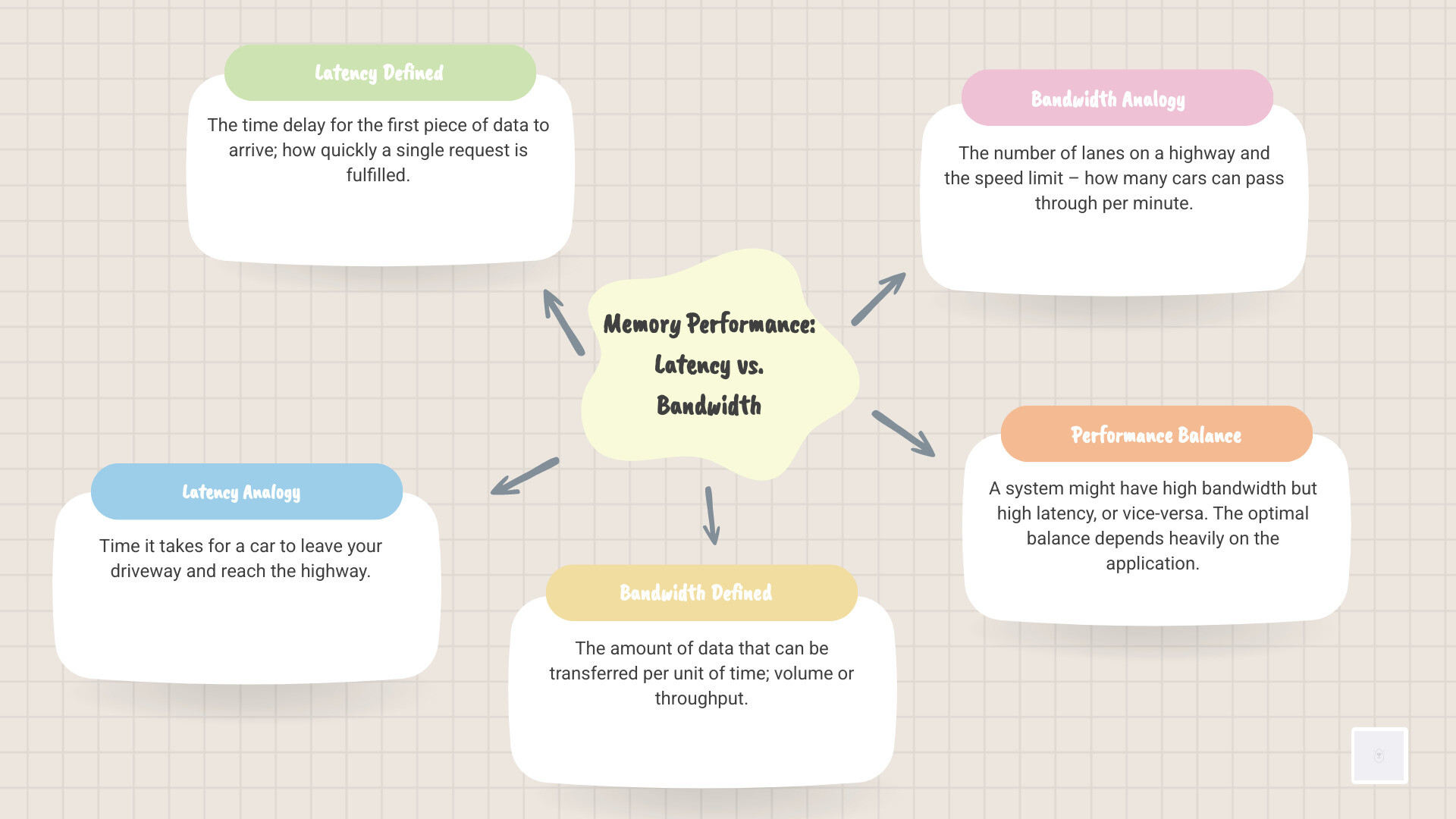
Latency vs. Bandwidth: A Performance Balancing Act
When discussing memory performance, it’s crucial to differentiate between latency and bandwidth. While both are vital, they measure different aspects of memory access and impact system performance in distinct ways.
- Memory Latency: As we’ve established, this is the time delay for the first piece of data to arrive. It’s about how quickly a single request is fulfilled. Think of it as the time it takes for a car to leave your driveway and reach the highway.
- Memory Bandwidth: This refers to the amount of data that can be transferred to or from the memory per unit of time. It’s about the volume or throughput. Think of it as the number of lanes on a highway and the speed limit – how many cars can pass through per minute.
An analogy often used is a highway system:
- Latency is like the time it takes for the first car to travel from an on-ramp to a specific exit. A short on-ramp and clear path mean low latency.
- Bandwidth is like the number of lanes on the highway. A highway with more lanes can handle more cars simultaneously, even if each car takes the same amount of time to travel a specific distance.
A system might have very high bandwidth (many lanes) but also high latency (long on-ramps and slow speed limits to get onto the highway). Conversely, a system could have low latency (quick access) but limited bandwidth (only one lane). The optimal balance depends heavily on the application.
Which is More Important for Overall Performance?
The relative importance of latency versus bandwidth is highly dependent on the workload.
- Latency-Sensitive Workloads: These are tasks that require the CPU to access small pieces of data frequently and cannot proceed until that specific data is available. The CPU might be “waiting” for data to perform its next operation. If it waits too long, it idles, wasting precious clock cycles.
- Examples include large database operations (especially those involving random access or pointer chasing), high-frequency trading, real-time analytics, and certain types of scientific simulations. In these scenarios, reducing the time to get the first bit of data is paramount.
- Bandwidth-Sensitive Workloads: These are tasks that require moving large blocks of contiguous data. The CPU requires a large amount of data, and it needs it quickly; however, the order or timing of receiving the first byte isn’t as critical as the overall throughput.
- Examples Include Video editing, large file transfers, rendering, and certain forms of data compression/decompression. Here, having a wide “pipe” to move data is more beneficial than how quickly the pipe opens.
Gaming Performance: This is a nuanced area. For many games, especially those played at lower resolutions or frame rates, the GPU is the primary bottleneck, and memory bandwidth (faster RAM speed) can have a more significant impact. However, in scenarios where the CPU becomes the bottleneck (e.g., high-refresh-rate gaming, complex physics simulations, or games with large open worlds), memory latency can become surprisingly significant. This is because the CPU might be waiting for instructions or small data packets from memory to process the next frame, making low latency crucial for maintaining consistent 1% low FPS and reducing stutter.
A balanced approach is often best. Modern systems benefit from both high bandwidth and low latency. As processor speeds continue to increase, the “memory wall” (where the CPU is frequently stalled waiting for memory) becomes more pronounced, making latency increasingly critical for overall system responsiveness.

The Real-World Impact of Low Latency Memory
The pursuit of low-latency memory isn’t just an academic exercise; it has tangible impacts on system performance, especially in demanding applications. While high bandwidth enables massive data throughput, low latency ensures that data is available precisely when the CPU needs it, thereby minimizing idle time and maximizing computational efficiency.
The impact of low latency is particularly evident in scenarios where the CPU is the primary bottleneck. This often occurs in applications that involve complex calculations, frequent data lookups, or rapid decision-making. Different CPU architectures also respond differently to memory latency. For instance, AMD’s Ryzen processors, especially those with the 3D V-Cache (X3D models), are known to be more sensitive to memory latency due to their Infinity Fabric interconnect. Intel platforms, while also benefiting from lower latency, tend to be less dramatically impacted in some scenarios.
Key Applications for Low Latency Memory
While all computing benefits from faster memory access, certain applications critically depend on low latency to achieve optimal performance:
- High-Frequency Trading (HFT): In financial markets, milliseconds can mean millions of dollars. HFT systems execute trades based on real-time market data, and the ability to process information and react faster than competitors is paramount. Low-latency memory is essential for rapid data ingestion, algorithmic decision-making, and order execution.
- Large Database Operations: Databases, particularly those with complex queries, random access patterns, or in-memory analytics, are highly sensitive to memory latency. Faster access to frequently used data pages and indices directly translates to quicker query responses and improved transaction processing throughput. For example, database transaction processing workloads can see significant performance gains from even small reductions in system-level memory latency.
- Scientific Computing and High-Performance Computing (HPC): Simulations, modeling, and data analysis in scientific research often involve massive datasets and iterative calculations. While HPC systems also demand high bandwidth, the ability to quickly access intermediate results or frequently used parameters from memory can drastically reduce computation times.
- High-Framerate Gaming: As discussed, for competitive gamers seeking maximum frames per second (FPS) and minimal input lag, especially on CPU-limited systems, low-latency RAM can significantly improve low FPS, reduce micro-stuttering, and provide a smoother, more responsive gaming experience.
- Real-time Analytics and AI/ML Inference: Applications that process and analyze data streams in real-time or perform rapid AI model inferences require immediate access to data. Low-latency memory ensures that data is fed to the processing units (CPUs or GPUs) without significant delays, enabling instantaneous insights and responses.
How Latency Affects Gaming and Different CPUs
In gaming, the impact of memory latency is often subtle yet crucial, especially for competitive players and those seeking extremely high frame rates. While average FPS might not always show a dramatic difference, low-latency RAM often improves 1% of low FPS and reduces stuttering. This means fewer sudden drops in frame rate, resulting in a smoother and more consistent visual experience, which is particularly critical in games.
The interaction between memory latency and CPU architecture is particularly noteworthy:
- AMD Ryzen X3D CPUs: AMD’s Ryzen processors, particularly the X3D variants (like the Ryzen 7 7800X3D or 9900X3D), feature a large L3 cache directly on the CPU die. This significantly reduces the CPU’s need to access main memory, as more data can be stored closer to the cores. However, when the CPU does need to access main memory, the design of AMD’s Infinity Fabric (the interconnect between CPU components) means that memory latency can still play a role. While the performance delta between “cheapest” and “best” DDR5 might be minor for X3D CPUs compared to non-X3D chips, optimal RAM (e.g., DDR5-6000 CL30) is still recommended as the price difference is often negligible in a high-end build. The optimal speed range for AMD’s AM5 Ryzen processors when running the Infinity Fabric at a 1:1 ratio is considered to be DDR5-6000 to DDR5-6400.
- Intel Core Series CPUs: Intel CPUs generally have a less pronounced sensitivity to memory latency compared to AMD’s Infinity Fabric architecture. However, they still benefit from lower latency, especially in CPU-intensive titles or scenarios. For Intel’s 12th, 13th, and 14th generation processors, DDR5 6000 CL30 or 6400 CL32 is generally recommended for optimal performance.
Optimal RAM Pairings:
- For the AMD Ryzen 5000 series (DDR4), 3600 CL16 is widely considered the optimal choice.
- For AMD Ryzen 7000 series (DDR5), 6000 CL30 is the sweet spot.
- For Intel 12th/13th/14th Gen (DDR5), 6000 CL30 or 6400 CL32 are excellent choices.
The performance difference between highly optimized DDR5 (e.g., 6000 CL30/32) and high-end DDR4 (e.g., 3200/3600 CL16/18) is approximately 10%. While the absolute latency in nanoseconds might not change significantly between, say, a 5600MT/s CL28 kit (10.0 ns) and a 7800MT/s CL36 kit (9.23 ns), the higher frequency of the faster kit still provides more bandwidth, which can be beneficial.
The Evolution and Future of Memory Technology
Memory technology has advanced significantly, continually evolving to meet the growing demands of processors and applications. While data transfer rates have soared, the true latency (in nanoseconds) has seen more gradual improvements, often due to deliberate trade-offs in manufacturing to prioritize cost-per-bit.
From DDR3 to DDR5: A Generational Shift
Each generation of Double Data Rate (DDR) Synchronous Dynamic Random-Access Memory (SDRAM) brings improvements in speed, efficiency, and capacity.
- DDR3 (Introduced ~2007): This generation typically operated at speeds ranging from 800 MHz to 2133 MHz. Common CAS latencies were CL9 to CL11. While widely adopted, its true latency was often in the 10-15 nanosecond range. For example, a DDR3-1600 CL9 would have a true latency of (9 * 2000) / 1600 = 11.25 ns. You can find historical DDR3 latency benchmarks on PassMark’s DDR3 Memory Latency Performance Charts.
- DDR4 (Introduced around 2014): DDR4 introduced higher speeds (2133 MHz to 4800+ MHz) and lower operating voltages. Despite higher CAS latency numbers (e.g., CL15 to CL19), the faster clock speeds meant that the true latency in nanoseconds often remained similar to or even improved slightly over DDR3. Modern DDR4 DIMMs can achieve latencies of under 15 ns, with top-tier kits like the 3600 CL14 being considered the “best-in-slot” for their generation.
- DDR5 (Introduced ~2020): The latest mainstream standard, DDR5, pushes speeds even further, starting from 4800 MHz and reaching well over 8000 MHz. While initial DDR5 kits often had higher CAS latencies (e.g., CL36 to CL40), the significantly increased data rates allowed for true latencies to remain competitive or even improve. For instance, a VENGEANCE DDR5 kit rated for 6000 MT/s with CL36 has a real latency of 12 nanoseconds. The fastest DDR5 kits typically achieve latencies in the 9-10 ns range, with some reaching as low as 9.375 ns (e.g., a DDR5-6500 kit). G.SKILL, for example, offers low-latency DDR5-6000 CL26 and CL28 memory kits, pushing the boundaries of what’s possible.
This phenomenon, where CAS latency numbers increase but true latency remains stable or improves, is sometimes referred to as the “latency paradox.” It highlights that raw speed (MT/s) and CAS latency must be considered together for a complete picture of memory performance.
Specialized and Future Low Latency Memory Technologies
Beyond the mainstream DDR evolution, several specialized memory technologies and architectural innovations are designed specifically to tackle latency challenges:
- RLDRAM (Reduced Latency DRAM): Unlike commodity DDR, RLDRAM is specifically engineered for low latency and fast random access. It achieves this through innovative circuit design that minimizes the time between the start of an access cycle and the availability of data. RLDRAM offers SRAM-like random access speeds while maintaining the high density of DRAM. It’s often used in high-performance networking equipment (e.g., 100GbE packet buffering and inspection) and specialized processing units where every nanosecond counts. Micron offers RLDRAM Memory in various densities, and GSI Technology also specializes in Low Latency DRAMs for advanced data networking.
- HBM (High Bandwidth Memory): While primarily focused on bandwidth, HBM also indirectly contributes to lower effective latency for certain workloads. By stacking DRAM dies vertically and integrating them directly onto the processor package (e.g., alongside a GPU or specialized accelerator), HBM drastically shortens the physical distance data travels, leading to extremely wide memory buses and immense bandwidth. This reduces the need to go “off-package” for data, which can improve overall system responsiveness.
- Tiered-Latency DRAM (TL-DRAM): This is a research-backed concept that aims to achieve both low latency and low cost-per-bit. TL-DRAM splits traditional long memory bitlines into shorter “near” and “far” segments. The “near” segment can be accessed with significantly lower latency, comparable to expensive short-bitline DRAMs, without the high cost. This allows for a tiered approach where frequently accessed data resides in the low-latency “near” segment.
- System-Level Innovations and Software-Defined Memory: The Future of Low-Latency Memory Isn’t Just About the DRAM Chip Itself. It also involves how memory is managed, accessed, and used at the system level. This includes advancements in memory controllers, interconnect technologies such as CXL (Compute Express Link), which enable memory pooling and disaggregation, as well as intelligent software layers. For enterprise and data center environments, optimizing memory access is critical for scaling performance and efficiency. Solutions that leverage Software-defined low latency memory can dynamically allocate and manage memory resources, reducing latency and improving utilization across distributed systems. These innovations are crucial for tackling the memory challenges posed by modern AI/ML workloads, large-scale databases, and high-performance computing.
The evolution of memory will continue to push the boundaries of speed and latency, driven by the insatiable demand for faster and more efficient computing.
Frequently Asked Questions about Low Latency RAM
Understanding memory latency can be complex, so let’s address some common questions.
Is lower CAS Latency (CL) always better?
Not necessarily. While a lower CL number indicates fewer clock cycles for the Column Address Strobe, the actual impact on performance depends on the memory’s overall speed (data rate). As we discussed, true latency is calculated in nanoseconds by factoring in both CL and the data rate. A higher-speed RAM with a slightly higher CL might still have the same or even lower true latency in nanoseconds than a lower-speed RAM with a lower CL. Always compare the true latency in nanoseconds, not just the CL number in isolation.
What is a good “true latency” for modern RAM?
For modern consumer systems, a “true latency” (in nanoseconds) of around 10 nanoseconds is generally considered excellent and represents a sweet spot for performance and cost. Many high-performance DDR4 kits (e.g., 3600 CL16) and optimal DDR5 kits (e.g., 6000 CL30) achieve this target. While it’s theoretically possible to go lower, the cost-to-performance ratio often diminishes significantly beyond this point for typical users.
Does RAM latency matter for a typical home or office PC?
For a typical home or office PC used for web browsing, word processing, email, and casual media consumption, RAM latency is of little concern. These applications are rarely CPU-bound by memory access, and the performance differences between various RAM latencies would be imperceptible to the user. In these scenarios, having sufficient RAM capacity is far more important than optimizing for ultra-low latency. Low-latency memory becomes critical in specific, demanding workloads like professional content creation, competitive gaming, large-scale data analysis, or scientific computing.
Conclusion
Memory latency is a fundamental aspect of computer performance, quantifying the time delay between a processor’s request for data and its retrieval from RAM. While often overshadowed by bandwidth, its significance is undeniable, particularly in CPU-intensive tasks and specialized applications. We’ve explored how latency is measured in clock cycles and nanoseconds, emphasizing that true latency in nanoseconds provides the most accurate comparison across different memory modules.
The transition from DDR3 to DDR5 exemplifies a relentless pursuit of higher speeds and enhanced efficiency. Despite increasing CAS Latency numbers, advancements in clock speeds have largely maintained or slightly improved true latency, keeping pace with processor demands. Specialized technologies, such as RLDRAM, and architectural innovations, like TL-DRAM, highlight the ongoing efforts to push the boundaries of low latency. Furthermore, system-level approaches, including software-defined low-latency memory, are paving the way for more intelligent and efficient memory management in complex computing environments.
Understanding the interplay between memory speed and latency empowers us to make informed choices when building or upgrading systems. While high bandwidth is crucial for throughput, optimizing for low latency ensures that data is delivered precisely when needed, minimizing idle CPU cycles and maximizing overall system responsiveness. As computing continues to evolve, the pursuit of lower-latency memory will remain a critical frontier in unlocking the full potential of next-generation hardware and applications.
Veeramachineni Lalitha
I am Finance Content Writer. I write Personal Finance, banking, investment, and insurance related content for top clients including Kotak Mahindra Bank, Edelweiss, ICICI BANK and IDFC FIRST Bank. My experience details : Linkedin